One-shot tensor decomposition of full-scale GC×GC-VUV datasets for resolving petrochemical groups (Paul-Albert Schneide, MDCW 2026)
- Photo: MDCW: One-shot tensor decomposition of full-scale GC×GC-VUV datasets for resolving petrochemical groups (Paul-Albert Schneide, MDCW 2026)
- Video: LabRulez: Paul-Albert Schneide: Decomposition of GCxGC datasets for resolving petrochemical groups (MDCW 2026)
🎤 Presenter: Paul-Albert Schneide (University of Copenhagen)
Abstract
Tensor decomposition methods such as PARAFAC and PARAFAC2 have been proposed for resolving co-elutions, and extracting purified spectra in two-dimensional chromatography datasets. However, the application of these methods is usually restricted to local regions-of-interest (ROIs). Therefore, additional pre-processing steps, are required and processing multiple samples at once can be difficult due to retention time shifts (e.g., it is difficult to define a ROI that captures the same analyse signal in multiple samples).
This work presents an application of fast, shift-invariant tensor decomposition, which was used for the decomposition of full-scale GCxGC-VUV datasets. The results show that chemical groups can be resolved, which are non-separable with conventional, template-based approaches, such as aliphates and olefines, Furthermore, the extracted peak areas are in good agreement with the quantitative results of the reference methods (e.g., bromine number for olefines).
Video Transcription
Background and Motivation
The project originated from a collaboration initiated by Alexandra Alvich from IFPEN, who approached Prof. Rasmus Bro’s research group at the University of Copenhagen for help analyzing a GC×GC-VUV dataset acquired during her PhD research. The work was then continued by Paul-Albert Schneider and Jesper Henri from the Technical University of Denmark.
The primary objective was to develop a simpler and less manually intensive approach for petrochemical group quantification while maintaining strong quantitative performance and spectral interpretability.
According to Schneider, the proposed method is based on two key principles:
- Simple implementation with a minimal number of tuning parameters
- Accurate estimation of peak patterns, VUV spectra, and peak areas
The workflow specifically targets group-level petrochemical analysis rather than individual compound identification.
Data Analysis Workflow
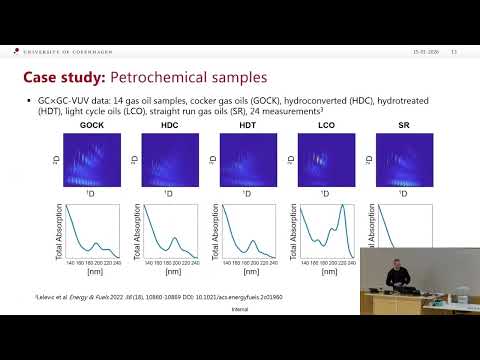
The presented workflow begins with a collection of GC×GC-VUV measurements. In this study, the researchers analyzed:
- 14 gas oil samples
- 24 total measurements, including replicates
- Samples processed using different treatment methods
Initial preprocessing was performed using a dedicated plug-in module developed during Alexandra Alvich’s PhD work. The preprocessing included:
- Signal smoothing
- Downsampling
- Basic data conditioning
The processed data were then submitted to the decomposition engine developed by the Copenhagen research group. The decomposition produced:
- Resolved VUV spectra
- GC×GC chromatographic landscapes
- Peak areas or peak volumes
An in-house spectral library from IFPEN was subsequently used to verify that the extracted spectra corresponded to known petrochemical groups, enabling group-level quantitative analysis.
Importantly, the workflow currently requires only a single major tuning parameter: the number of components used in the decomposition model. The researchers also noted ongoing efforts to automate this selection step.
Comparison with Existing Template-Based Methods
The study benchmarked the new approach against Alexandra Alvich’s previously developed template-based quantification method.
In the template-based workflow:
- Elution regions are predefined using a grid structure
- Peak intensities within those regions are summed
- Quantitative estimates are obtained for specific petrochemical classes
Although the template-based strategy demonstrated strong performance compared with other analytical techniques, Schneider highlighted several limitations:
- Sensitivity to retention time shifts
- Manual adjustment of integration regions
- Dependence on prior knowledge of coeluting compounds
The new decomposition-based method was designed to reduce manual intervention and improve robustness against chromatographic variability.
Shift-Invariant Trilinear Decomposition
The proposed workflow is conceptually related to PARAFAC and multivariate curve resolution methods.
One important advantage of GC×GC-VUV data is the applicability of the Beer–Lambert law, which enables mathematically structured decomposition approaches.
The researchers evaluated two possible strategies:
- Decomposing each sample individually
- Decomposing all samples simultaneously after concatenation into one large dataset
The second strategy became the central focus of the work. Multiple samples were concatenated into a large matrix and factorized to extract shared chemical information across all measurements simultaneously.
Unlike many conventional GC×GC deconvolution pipelines, the workflow does not rely on a prior region-of-interest detection step. Instead, the entire dataset is decomposed directly.
Addressing Retention Time Shifts
A critical challenge for PARAFAC-type models is the assumption of strict trilinearity. In GC×GC datasets, however, second-dimension retention time shifts caused by temperature programming violate this assumption.
Schneider demonstrated how standard one-component PARAFAC models fail to properly model shifted peaks, leaving characteristic residual patterns. When fitting additional components, conventional models often allocate extra components to describing peak shifts instead of resolving true coeluting compounds.
The shift-invariant model solves this issue by explicitly accounting for chromatographic shifts. As a result:
- Large shifted peaks are modeled correctly
- Residuals are minimized
- Small coeluting peaks become resolvable
The algorithm uses fast Fourier transform (FFT)-based operations internally to correct for chromatographic shifts efficiently.
According to the presentation, the approach is also significantly faster than PARAFAC2, which is commonly used for shifted datasets.
The researchers additionally described extensions of the model that can accommodate:
- Retention time shifts
- Peak shape variations
- Additional flexibility without losing uniqueness properties
Quantitative Results
The team applied a seven-component model to the complete dataset containing 24 GC×GC-VUV measurements.
The decomposition extracted seven characteristic VUV spectra, which were compared against the IFPEN in-house spectral library. The extracted spectra matched known petrochemical group signatures very well.
The resolved components included:
- Two monoaromatic components
- Two diaromatic components
- Additional petrochemical group patterns
For quantitative evaluation, chemically related components were grouped together.
Reproducibility
Replicate measurements demonstrated strong quantitative reproducibility:
- Relative standard deviations below 10%
- Consistent peak area estimation across petrochemical groups
Comparison with the Template-Based Approach
The decomposition workflow showed good agreement with the existing template-based quantification strategy, with monoaromatics representing the main discrepancy requiring further investigation.
Schneider explained that the differences were likely related to relative response factor scaling used in the template-based method but not yet implemented in the decomposition workflow at the time of the presentation.
Future Development
The researchers outlined several next steps for the project:
- Running models on individual samples to achieve higher resolution
- Resolving sulfur-containing compounds
- Extracting more sample-specific differences
- Automating component number selection
- Investigating deviations in monoaromatic quantification
- Integrating the workflow into an open-source software project
The team also expressed interest in future collaboration with other researchers working on related GC×GC data analysis workflows.
Conclusion
The presented shift-invariant trilinear decomposition workflow demonstrated promising performance for automated petrochemical group analysis in GC×GC-VUV datasets. By combining robust mathematical modeling with minimal manual intervention, the method offers a simplified alternative to traditional template-based approaches while maintaining strong quantitative agreement and spectral interpretability.
The work highlights the growing role of advanced multivariate data analysis strategies in comprehensive chromatography and demonstrates how shift-aware decomposition methods can significantly improve the analysis of highly complex petrochemical datasets.
This text has been automatically transcribed from a video presentation using AI technology. It may contain inaccuracies and is not guaranteed to be 100% correct.